Rails6 で csv エクスポートを実装(複数テーブル編)
この記事では、Rails6 + MySQL 環境でテーブル内容を csv としてエクスポートするメソッドを実装して、その速度比較をします。
ここでは user has_many projects の関係をもたせています。
そこで CSV には user 情報だけでなく、ueer が属している project の情報も合わせて出力することにします。(以前の記事での project の CSV 出力は project テーブルの情報だけを出力していました)
結論としては以下の様に実装方法により大きな差がでました。
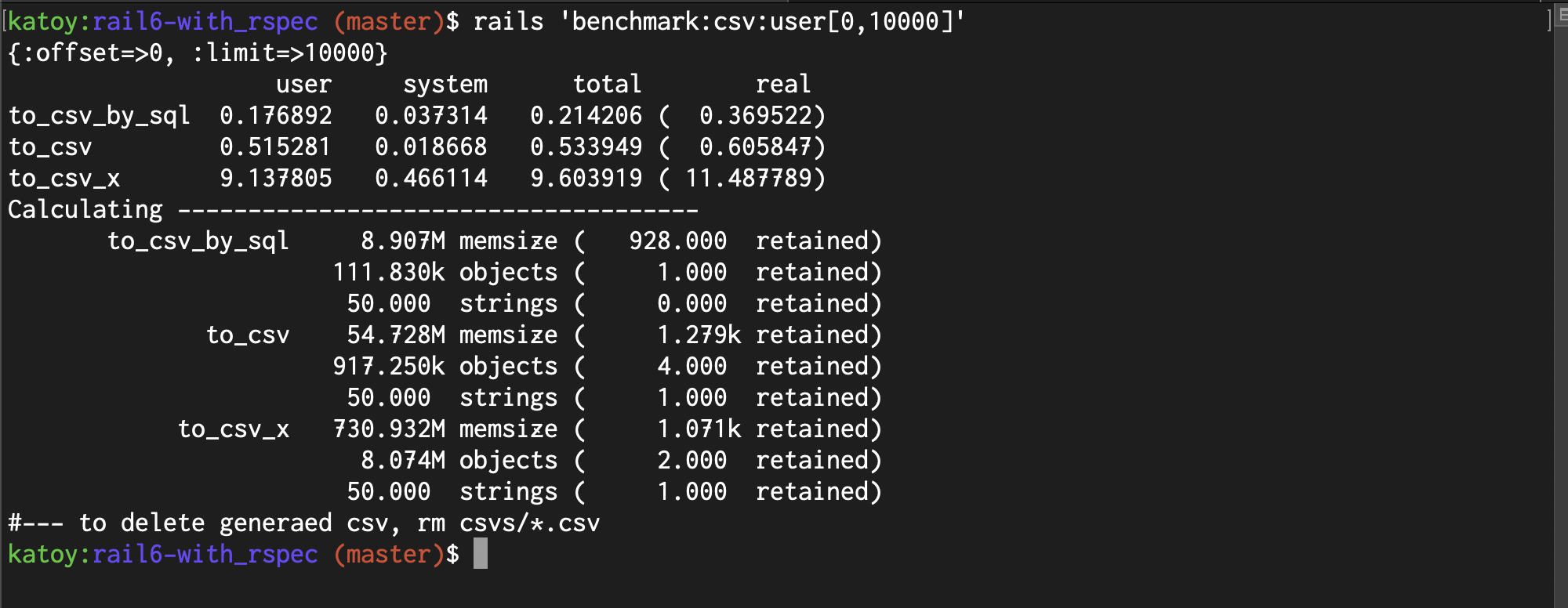
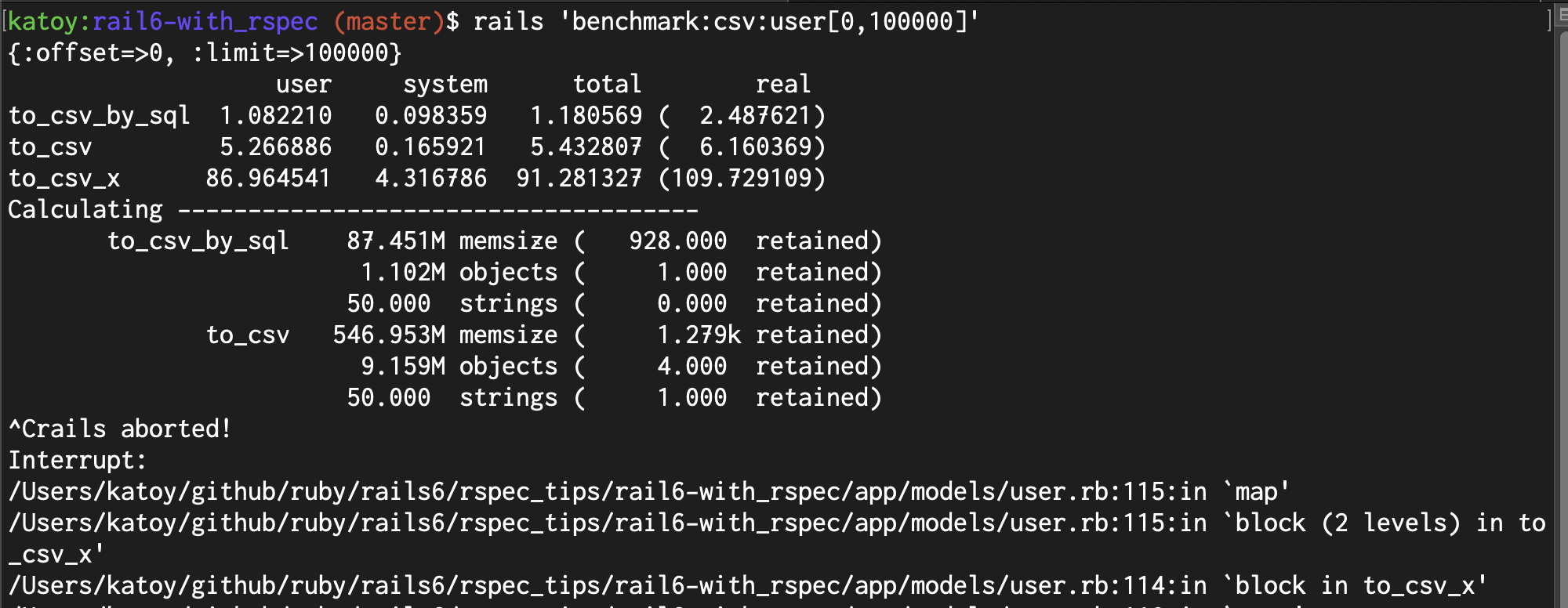
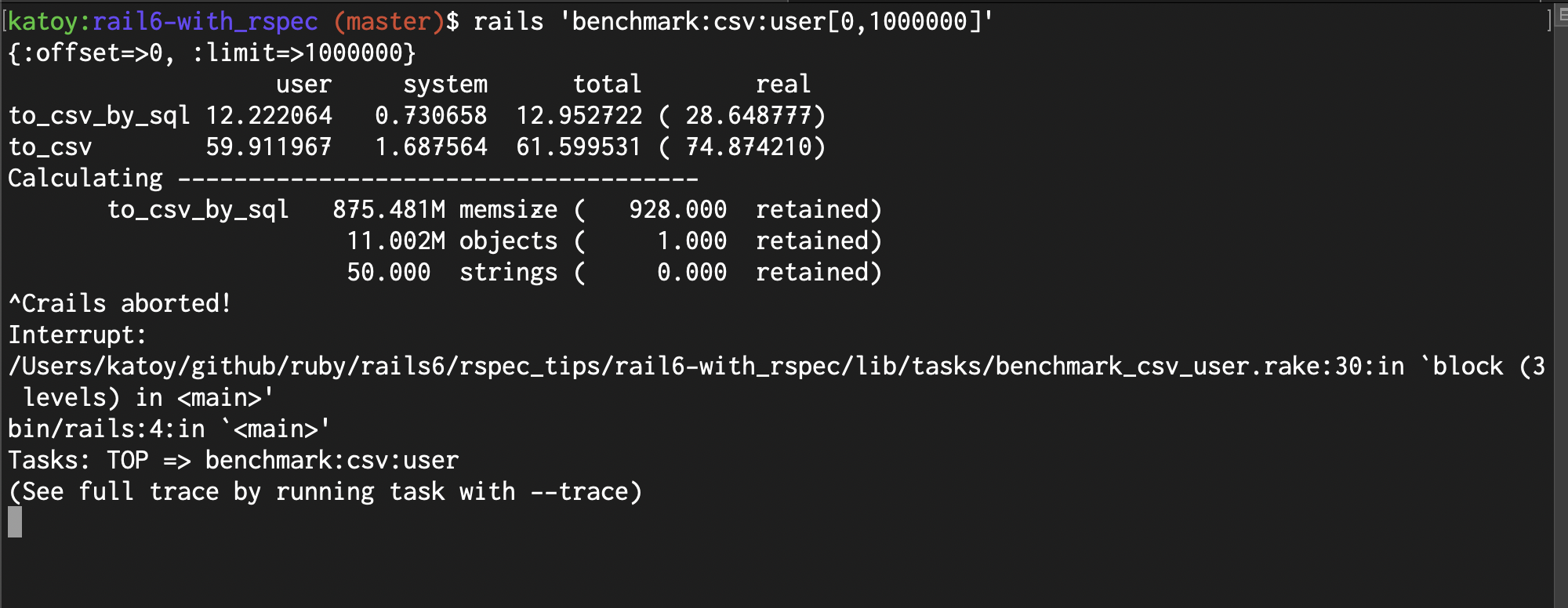
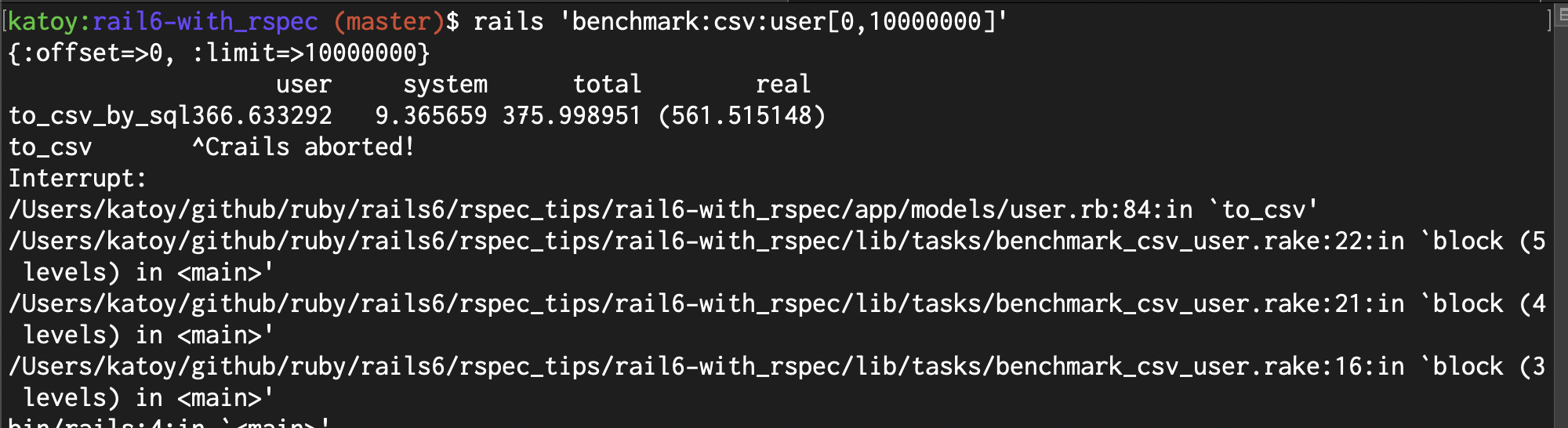
| 1,000件 | 10,000件 | 100,000件 | 1,000,000件 | 10,000,000件 | |
| 実装_1(SQL) | 0.14 | 0.3 | 2.4 | 28.6 | 561.5 |
| 実装_2(in_batches) | 0.07 | 0.6 | 6.1 | 74.8 | ー |
| 実装_3(each) | 1.18 | 11.4 | 109.7 | ー | ー |
数万件程度の処理なら、どの実装も十分実用には耐えると思われます。ただし 1千万件オーダー、それ以上の件数を扱うなら、実装方法を吟味する必要があります。
この測定結果を得るコードや測定方法が妥当なのかは、以下を読んで各自で判断してみてください。
1. メソッドの実装
3 つの実装をしました。コードはそれぞれのリンク先を参照してください。
1 to_csv_by_sql() MySQL の CSV 出力機能を利用した実装です。
2. to_csv() in_batches() メソッドを利用して、1000 件ごとにバッチ処理する実装です。
3. to_csv_x() 単純に where 結果を each でループする実装です。
user と project の関係は schemaspy で作成した ER図も参照してください。
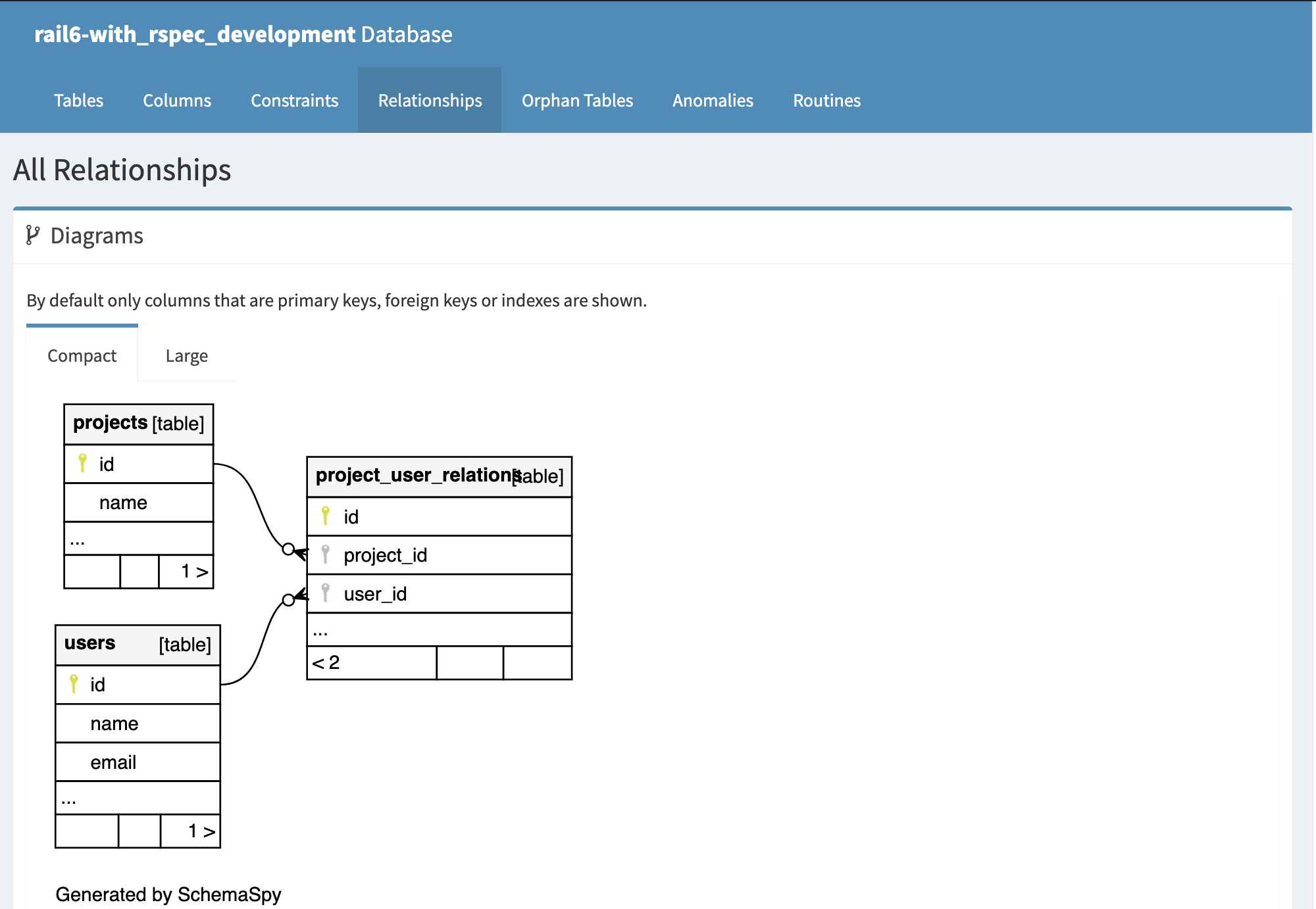
CSV は user.id, user. name, user. last_login_at, project.name の情報を出力します。
user ごとに1行の CSV を出力するのではありません。
- user が projec に属していなければporject 情報列は 空になっている一行だけ出力します。
- user が 1つだけの project の属していれば project 情報は所属 project の情報が埋まっている一行だけ出力します。
- user が複数の project に属していれば、属しているproject の数文の行をそれぞれの project 情報を埋めて出力します。
つまり SQL で user に projects を left outer join した結果を CSV 出力すると考えていただければ十分です。
CSV の行の順番は, users.id の昇順, projects.id の昇順 とします。
to_csv_x() では、単純に User.all で ループし、各 user ごとに user.projects でループしています。
csv = CSV.new(file, **csv_options)
users.in_batches.each_record do |row|
project_names = row.projects.order(:id).map(&:name)
last_login_at = row.last_login_at&.strftime(CSV_DATETIME_FORMAT)
if !project_names.empty?
project_names.each do |p_name|
csv << [row.id, row.name, last_login_at, p_name]
end
else
csv << [row.id, row.name, last_login_at, ""]
end
end
|
to_csv では、users と project を join して join 結果の行数でループしています。
users = User.where(id: users.first.id..users.last.id)
.left_joins(:projects)
.select(select_sql)
.order("users.id ASC, projects.id ASC")
File.open(csv_name, 'w:UTF-8') do |file|
file.write BOM
csv = CSV.new(file, **csv_options)
users.in_batches.each_record do |row|
last_login_at = row.last_login_at&.strftime(CSV_DATETIME_FORMAT)
csv << [row.id, row.name, last_login_at, row.project_name]
end
end
|
to_csv_x() は in_batch を使ってはいますが、 N+1 問題を含んでいます。
CSV の行数だけ SQL 文が発行されてしまうのです。
to_csv() では、SQL 発行は 1 回です。
SQL の発行回数は 次のテストの章で pry を使って確認してみます。
SQLの発行回数の差が実行速度にどう影響するかはベンチマークの章で確認します。
user.last_logine_at 列は datetime です。 to_csv_by_sql() では 列の値を +9:00 時間して出力することにしました。その処理をしたので 3 つの実装すべてで同一の列情報が出力されます。
UTC_OFFSET = '+09:00'
...
select_sql = <<-SQL.squish
users.id,
users.name,
CASE
WHEN users.last_login_at IS NULL THEN ''
ELSE convert_tz(users.last_login_at, '+00:00','#{UTC_OFFSET}')
END AS last_login_at,
CASE
WHEN projects.name IS NULL THEN '' ELSE projects.name
END AS project_name
SQL
|
参考情報:
- https://www.dbonline.jp/mysql/function/index48.html
CONVERT_TZ関数 (指定した日時のタイムゾーンを変更した値を取得する)
2. メソッドのテスト
それぞれのメソッドについて rspec でのテストを書きました。
spec/models/user_spec.rb で参照できます。

test 環境 (レコード数が少ない状態) で 3 つのCSV 出力メソッドを呼び出して、発行される SQL を確認してみます。
user_spec.rb の to_csv_by_sql のテスト部に binding.pry を追加して ブレークポイントを設定します。そして rm log/test.log してから rspec spec/moddes/user_sper.rb:110 として to_csv_by_sql() のテストを走らせます。
プログラム実行が bindig.pry の秒で停止したら、 別端末で、 tail -f log/test.log をします。rspec 字実行端末にもどり、User.to_csv() を入力し Enter キーを入力します。
すると、tail- f の実行端末に実行された SQL が表示されます。
同様にして、 to_csv_x() を実行したときの SQL 内容、 to_csv_by_sql() を実行したときの SQL 内容を表示させます。
break point の設定
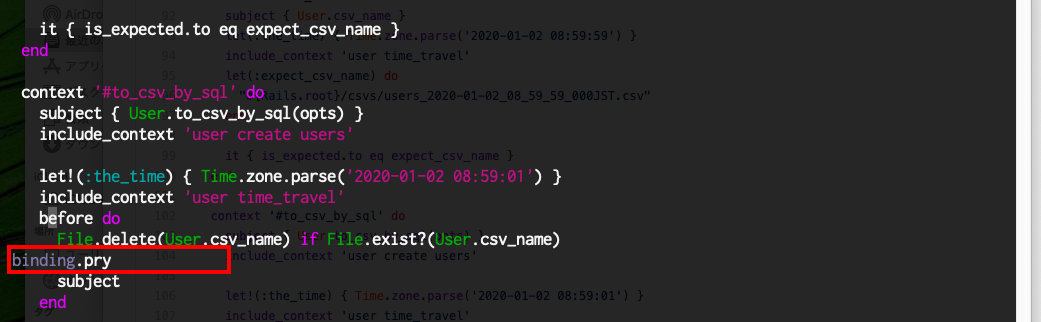
rspec を実行してbreak point で停止させる
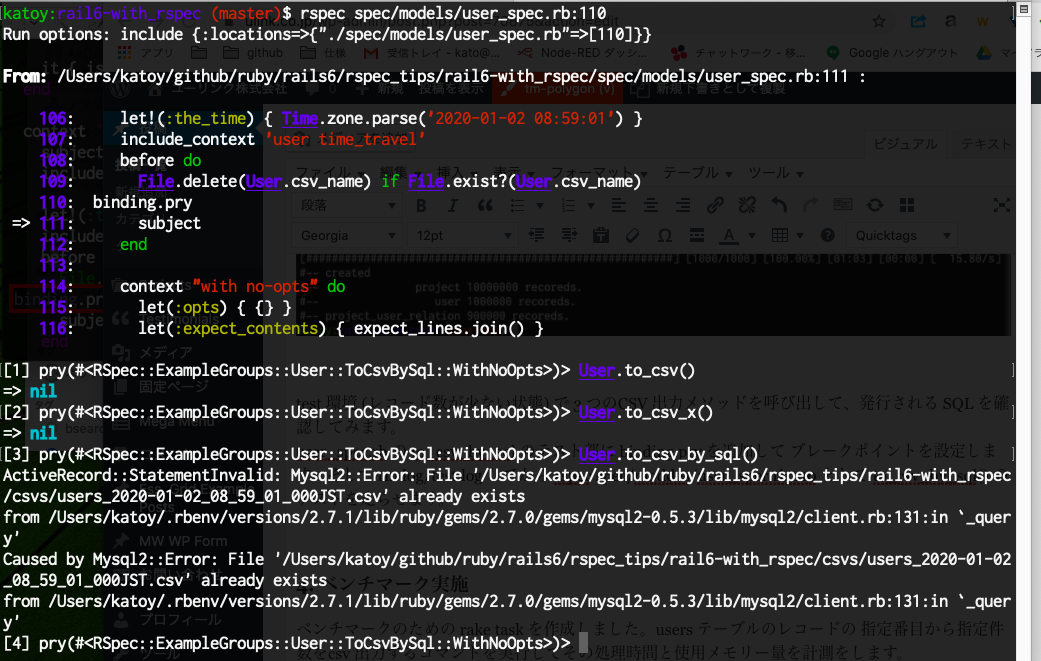
User.to_csv() 実行時の SQL
to_csv() は 1000 件ごとに 1 つの SQL が実行されます。test DB には 数件しか user レコードがないので、 1つのSQLだけが実行されます。次の章で大容量 DV をつくった後に、user を2000 件処理して、SQL が 複数回実行されることを確認することにします。
User.to_csv_x() 実行時の SQL
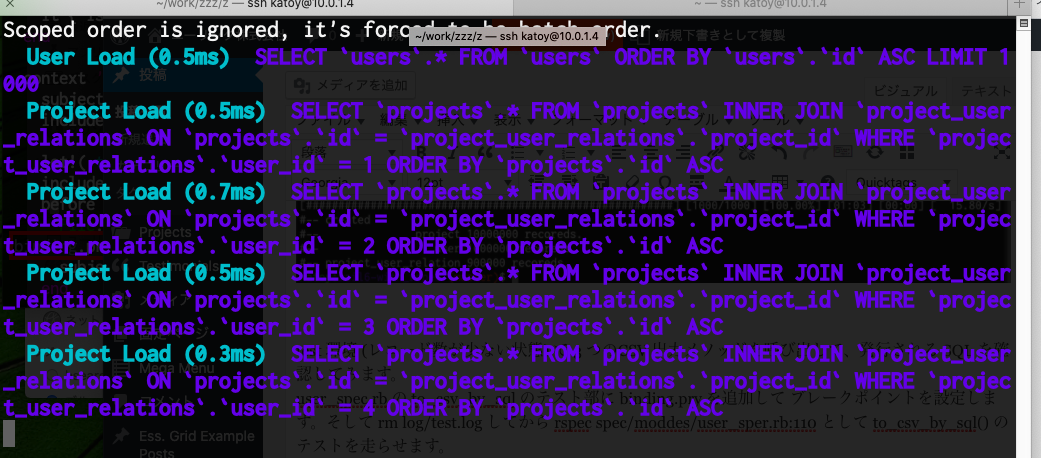
ti_csv_x() は users を select する SQL だけでなく、各 user ごとに projects を select する SQL が実行されています。
これがいわゆる N+1 問題です。この実装では大量のSQLが発行されます。対象レコードの件数が多い場合、実用に耐えない処理時間になってしまいます。
参考情報: https://qiita.com/muroya2355/items/d4eecbe722a8ddb2568b SQLクエリのN+1問題
to_csv_by_sql() 実行時のSQL
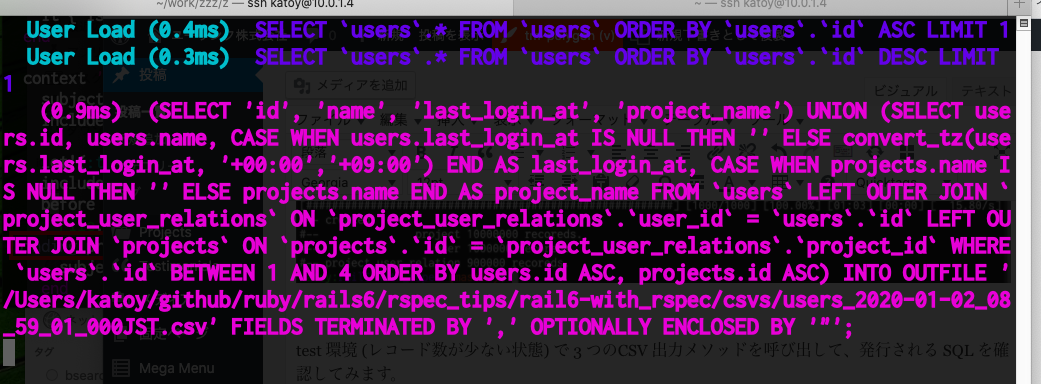
to_sql_by_sql() は、user のレコード数に関係なく常に 1 つの SQL が実行されます。
3. 大容量DBの作成
$ rails 'db:make_big_db[10000000,1000000]'
として、 Project テーブルに 1千万件, User テーブルに 1千万件を登録します。
user と project の関係は 10 user ごとに 所属する project 数が [0, 1, 0, 0, 0, 3, 0, 0, 5, 0] となるように登録しています。(つまり 中間テーブル project_users_relation には 900万件登録)
実行には 40分かかりました。(すぐに rails db:dump して dump を取りました)
この rake task の内容は lib/tasks/make_big_db.rake で参照できます。
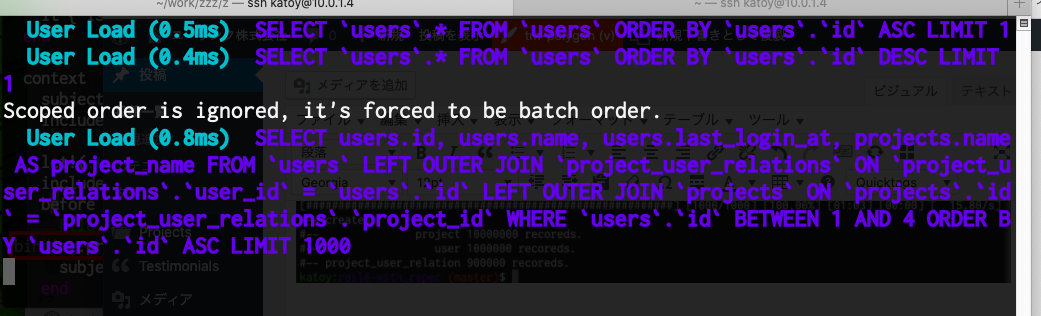
先頭の 2000 件を to_csv() で csv 出力して、そのときに実行される SQL を確認してみます。
rails c としてコンソールに入ります。そして User.to_csv(offset:0, limit:2000) を実行します。

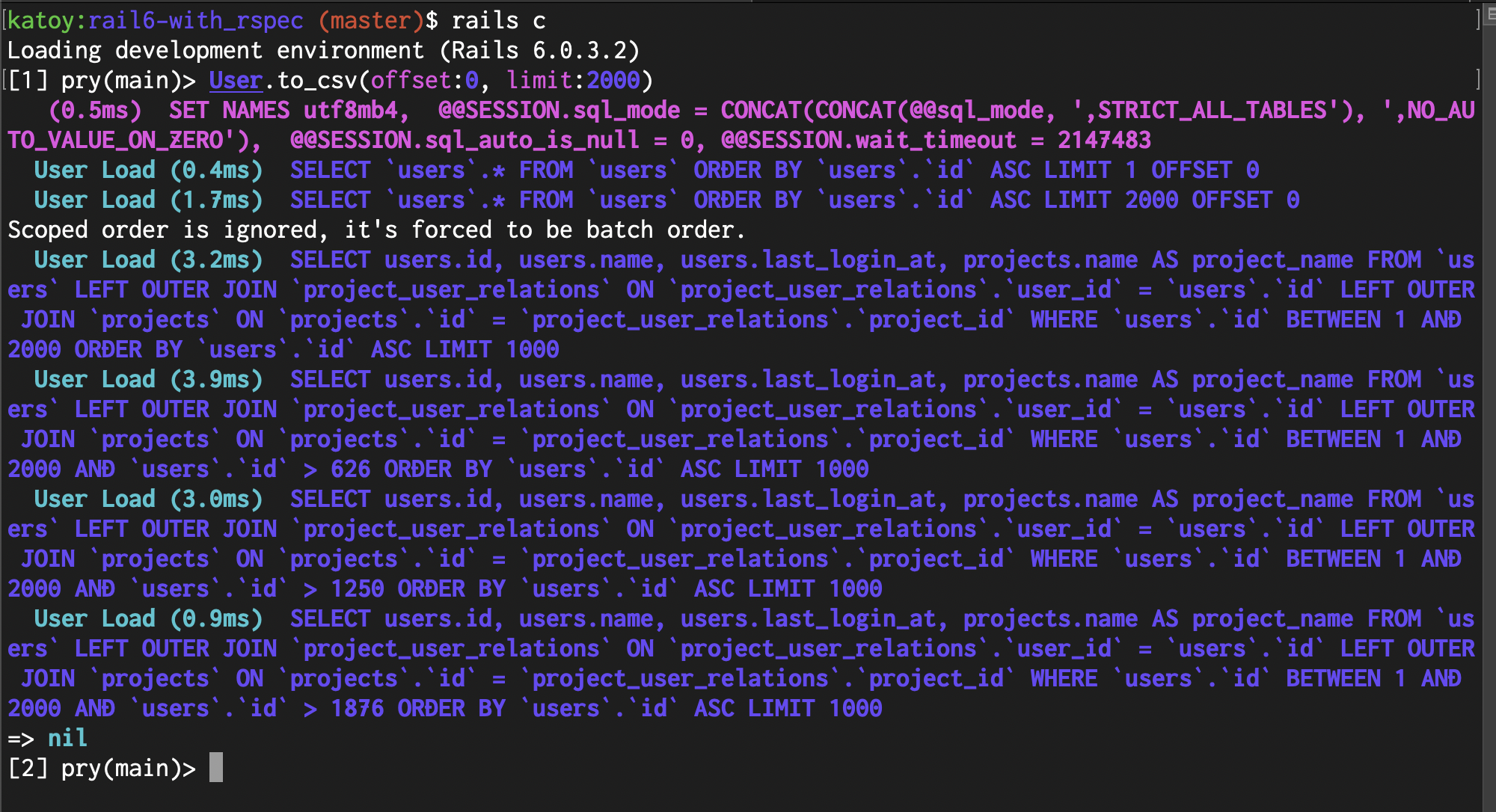
4 つの SQL が実行されています。 user 1000 件ごとではなく、 users と projects を left outer join した結果のテーブルを 1000 県ごとに処理しているので、こ0の場合は 2 つのSQLではなく、4 つの SQL が実行されています。
ここでは、スクリーンショットは示しませんが、to_csv_by_sql(offset:0, limit:2000) や to_csv_x(offset:0, limit:200) を実行させて、どんな SQL が実行されるかを確認してみてください。(to_csv_x() は liit:2000 でなく、 limt:200 ぐらいで試してください)
to_csv_by_sql() では 1 つの SQLが実行されます。to_csv_x() では多量の SQL が実行されます。
rails c の画面に表示される SQL は log/development.log にも記録されています。 less -R log/development.log などとして閲覧してみてください。
4. ベンチマーク実施
ベンチマークのための rake task を作成しました。users テーブルのレコードの 指定番目から指定件数をcsv 出力するコマンドを実行してその処理時間と使用メモリー量を計測をします。
lib/tasks/benchmark_csv_user.rake でコードを参照できます。
計測環境:
- PC MacBook Pro (CPU 2.3 GHz, クアッドコア Intel Core i5,メモリー 16GB)
- OS Catalina 10.15.5
- ruby 2.7.1p83 (2020-03-31 revision a0c7c23c9c) [x86_64-darwin19]
- rails 6.0.3.2
- MySQL Ver 8.0.19 for osx10.15 on x86_64 (Homebrew)
| 1,000件 | 10,000件 | 100,000件 | 1,000,000件 | 10,000,000件 | |
| 実装_1(SQL) | 0.14 | 0.3 | 2.4 | 28.6 | 561.5 |
| 実装_2(in_batches) | 0.07 | 0.6 | 6.1 | 74.8 | ー |
| 実装_3(each) | 1.18 | 11.4 | 109.7 | ー | ー |
| 1,000件 | 10,000件 | 100,000件 | 1,000,000件 | 10,000,000件 | |
| 実装_1(SQL) | 1 | 8 | 87 | 875 | ー |
| 実装_2(in_batches) | 5 | 54 | 546 | ー | ー |
| 実装_3(each) | 73 | 730 | ー | ー | ー |
SQL での実装でも 1千万件での処理時間は厳しいです。非同期処理にするといった工夫が必要と思われます。
ActiveRecord の each 実装は N+1問題のために in_batches での実装より 20 倍程度遅くなっています。

5. まとめ
- N+1 問題を避けることは必須。
- SQL での csv 出力実装でも1千万件は分単位の時間がかかる。
- SQL の CONVERT_TZ関数を利用して、datetime を timezone に合わせた値に変換できる。
つぎは、user – project の情報の CSVインポートを複数の方法で実装し、処理速度・メモリー使用量を比較していきます。