Rails6 で csv インポートを実装
この記事では、Rails6 + MySQL 環境で CSV ファイルをインポートしてテーブルにレコード登録するメソッドを実装して、その速度比較をします。
結論としては以下の様に実装方法により大きな差がでました。
| 1,000件 | 10,000件 | 100,000件 | 1,000,000件 | 10,000,000件 | |
| 実装_1(SQL) | 0.04 | 0.09 | 0.5 | 7.3 | 129.1 |
| 実装_2(insert_all) | 0.21 | 1.79 | 17.2 | 183. 8 | ー |
| 実装_3(each) | 5,41 | 49.98 | ー | ー | ー |
数万件程度の処理なら、どの実装も十分実用には耐えると思われます。ただし 1千万件オーダー、それ以上の件数を扱うなら、実装方法を吟味する必要があります。
この測定結果を得るコードや測定方法が妥当なのかは、以下を読んで各自で判断してみてください。
1. メソッドの実装
インポートについても3つの方法で実装をしました。コードはリンク先で参照できます。
1 import_by_sql SQL で CSV ファイルをインポートとする実装です。
2 imorrt inert_all を使って 1000 行ごとに insert 処理する実装です。
3 import_x 1 行ごとに insert をする実装です。
2. メソッドのテスト
3 つのインポート実装それぞれに対して、 spec/fixtures/export_projects.csv を import した後の DB 内容を比較するテストをしています。
それぞれのテストは以下のリンクから参照してください。
- import_by_sql SQL文で CSV を import する実装です。
- import 1000 行ごとに insert_all する実装です。
- import_x CSV 一行ごとに find_or_create する実装です。
本来なら、DB内容はすべて同じになるべきですが、現状実装ではそうなっていません。
SQL での import と ActiveRecord での import で、 datetime の列の値が 9時間ずれるのです。。
その原因は、Rails での timezone は Asia/Tokyo 、MysQL の timezone は UTC としていることに起因しています。
CSV ファイルの “202-01-01 01:02:03” は ActiveRecord 経由では Time.zon.parse(“2020-01-01 01:02:03”) で扱っています。(CSV ファイルを Excel などで閲覧したとき、JST のほうがユーザーにとっては自然です)
SQL で読み込む時は “2020-01-01 01:02:03″ が直接 DB に UTC として取り込まれます。それを ActiveRecord 経由で読み込むと、+9:00 された 2020-01-01 10:02:03” となってしまいます。
このへんのことは、 Rails, DB, csv での timezone をどうするかの仕様をはっきりさせて、それに沿った実装することでTimezone の解釈間違いを無くようにすることが必要になります。
SQL での import 時に datetime の offset 操作を組み込めれば rspec で 同じ DB 結果になるというテストが書けたはずなのですが、その方法がわかりませんでした。ここでの目的は CSV インポートの速度比較なので timezone の扱いは手を抜いています。
3. 大容量 CSV の作成
大容量の project レコードの CSV を作る rake task をつくりました。
lib/tasks/make_big_csv.rake で参照できます。
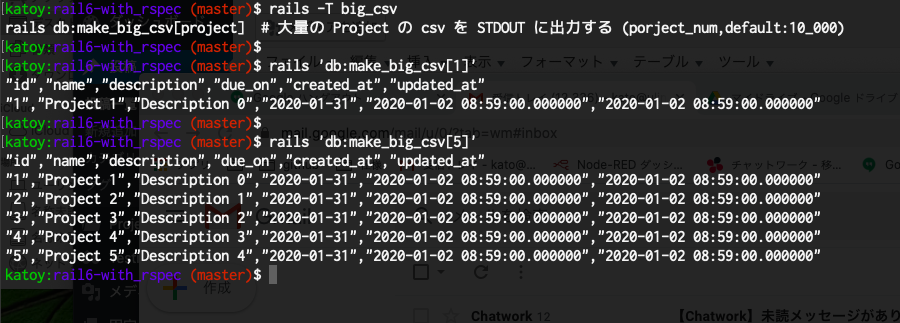
実際に CSV ファイルを作る時は rails ‘db:make_big_csv[1000]’ > csvs/1000.csv のようにします。
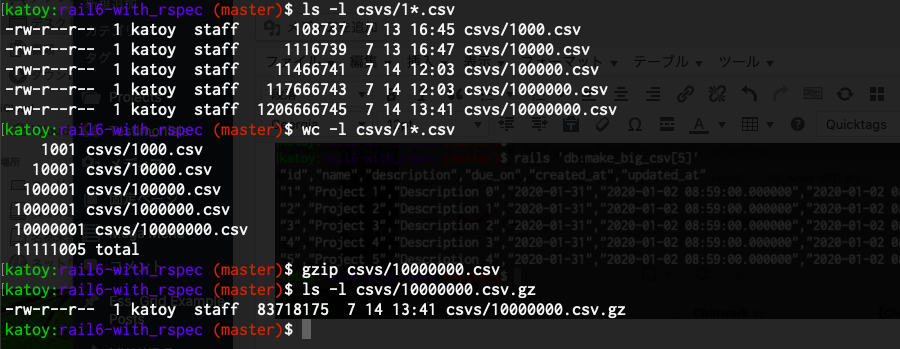
1千万行の CSV は 1GB程度になります。普段は gzip しておいて、使うときだけ gunizp するとよいです。unzip すると 80MB 程度になります。
4. ベンチマーク実施
3 つの実装に対して指定ファイルを import して。その実行速度、使用メモリー量を計測する rake task をつくりました。
lib/tasks/benchmark_csv_project.rake で参照できます。

次のコマンドを実行して計測をしていきます。
$ rails ‘benchmark:import:project[csvs/1000.csv]’
$ rails ‘benchmark:import:project[csvs/10000.csv]’
$ rails ‘benchmark:import:project[csvs/100000.csv]’
$ rails ‘benchmark:import:project[csvs/1000000.csv]’
$ rails ‘benchmark:import:project[csvs/10000000.csv]’
1万行で import_x は メモリー使用量測定がなかなか終了しなくなったので、 それ以降の測定では import_x メソッドは測定から外しました。(コメントアウトしました)
10万行で import のメモリー使用量測定は数分かかったので、それ以降は ctrl-c で中断をしました。
| 1,000件 | 10,000件 | 100,000件 | 1,000,000件 | 10,000,000件 | |
| 実装_1(SQL) | 0.04 | 0.09 | 0.5 | 7.3 | 129.1 |
| 実装_2(inert_all) | 0.21 | 1.79 | 17.2 | 183. 8 | ー |
| 実装_3(each) | 5,41 | 49.98 | ー | ー | ー |
| 1,000件 | 10,000件 | 100,000件 | 1,000,000件 | 10,000,000件 | |
| 実装_1(SQL) | 0.07 | 0.07 | 0.07 | 0.07 | ー |
| 実装_2(insert_all) | 12.1 | 122.1 | ー | ー | ー |
| 実装_3(each) | 396.7 | ー | ー | ー | ー |
SQL をつかった実装でも 1千万件までぐらいまでが限界です。
insert_all をつかった実装では 100万件ぐらいまでが限界です。
(本番サーバーの能力が PCの 10倍, 100 倍あれば、1千万件以上も可能とおもわれます)
CSV インポートは CSVインポートよりは重い処理になります。DB の index 更新処理が必要なのもその一因です。
5. まとめ
SQL の CSV インポート機能を使う実装でも 1千万件程度が限界です。
ActiveRecord の insert_all で 1000件ごとに SQL 発行するようにしても SQL 実装より 100 倍ほど遅いです。
インポート実装では, timezone の扱いに注意が必要です。
次の記事では、 user has_many projects の関係がある場合に user + project の情報を CSV エクスポートする実装の速度・メモリー使用量を比べていきます。